Zero-Shot Object Detection
* SRI International, Princeton, NJ
^ NEC Labs America, Cupertino, CA
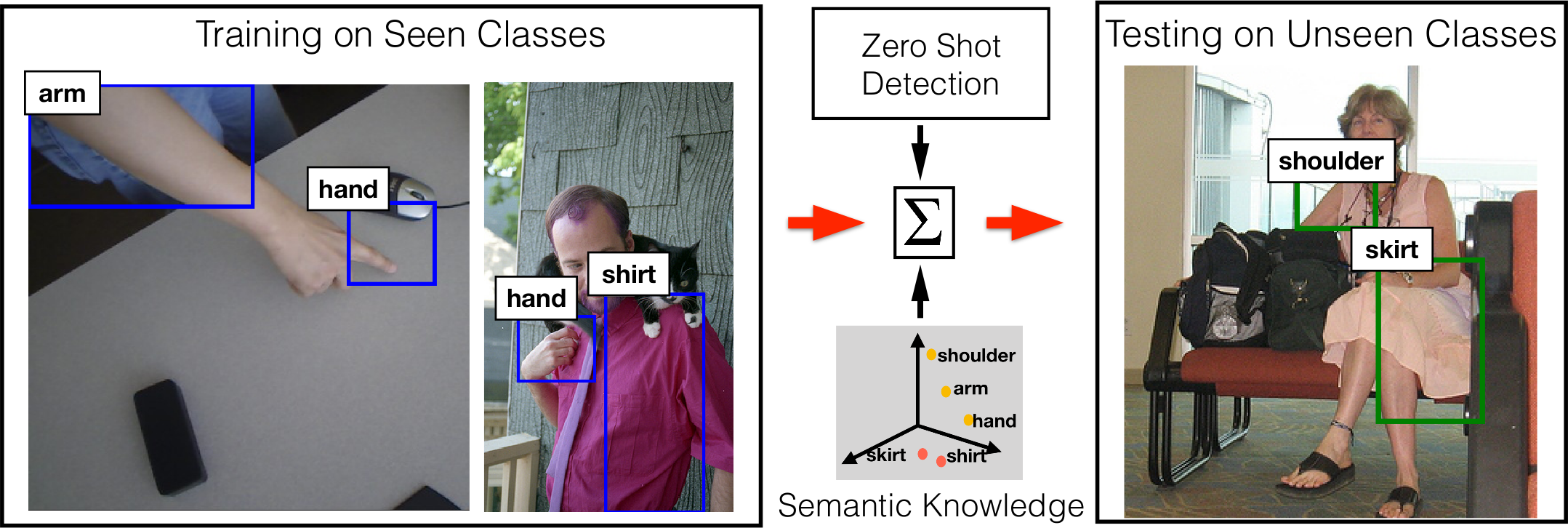 |
Fig. 1: We highlight the task of zero-shot object detection where object classes “arm”, “hand”, and “shirt” are observed (seen) during training, while classes “skirt”, and “shoulder” are not seen. These unseen classes are localized by our approach that leverages semantic relationships, obtained via word embeddings, between seen and unseen classes along with the proposed zero-shot detection framework. The example has been generated by our model on images from VisualGenome dataset.
Abstract: In this work, we introduce and tackle the problem of zero-shot object detection (ZSD), which
aims to detect object classes which are not observed during training. We work with a
challenging set of object classes, not restricting ourselves to similar and/or fine-grained
categories cf. prior works on zero-shot classification. We follow a principled approach by
first adapting visual-semantic embeddings for ZSD. We then discuss the problems associated
with selecting a background class and motivate two background-aware approaches for learning
robust detectors. One of these models uses a fixed background class and the other is based
on iterative latent assignments. We also outline the challenge associated with using a
limited number of training classes and propose a solution based on dense sampling of the
semantic label space using auxiliary data with a large number of categories. We propose
novel splits of two standard detection datasets – MSCOCO and VisualGenome, and discuss
extensive empirical results to highlight the benefits of the proposed methods. We provide
useful insights into the algorithm and conclude by posing some open questions to encourage
further research.
Results
We highlight the results obtained on unseen classes in the following figure.
 |
 |
 |
 |
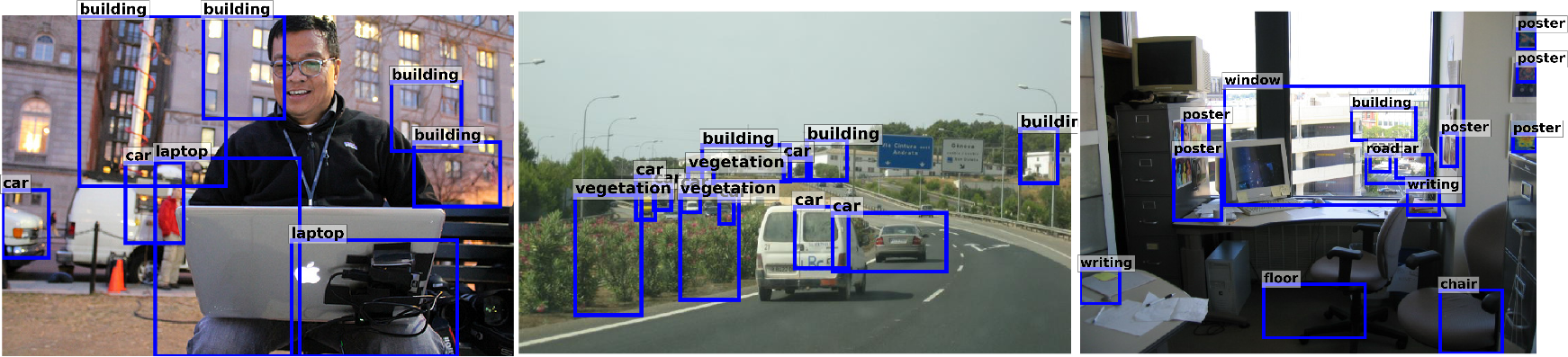
Fig. 2: This figure shows some detections made by our background-aware methods. We have used Latent Assignment Based (LAB) model for VisualGenome (rows 1-2) and the Static Background (SB) model (rows 3-4) for MSCOCO. Reasonable detections are shown in blue and two failure cases in red. This figure highlights the effectiveness of our methods in being able to detect unseen classes in a zero-shot setting.
Downloads
We are releasing our seen and unseen class names and train and test splits. This is an attempt to standardize the work done in this area.
VG
Train and Test splits
Seen and Unseen classes
Synset-Word Dictionary
MSCOCO
Train and Test splits
Train Bounding Boxes (Note that these bounding boxes are from about 44,000 unique images. We started with about 73k images and after removing those with unseen classes, were left with 44k images.)
Seen and Unseen classes
Synset-Word Dictionary
Paper
Our paper is available here. I also wrote a short blog post about the paper.
If you found the paper and data useful, please consider citing our paper using the bibtex:
@inproceedings{bansal2018zero,
title={Zero-Shot Object Detection},
author={Bansal, Ankan and Sikka, Karan and Sharma, Gaurav and Chellappa, Rama and Divakaran, Ajay},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={384--400},
year={2018}
}
Acknowledgments
This project is sponsored by the Air Force Research Laboratory (AFRL) and Defense Advanced
Research Projects Agency (DARPA) under the contract number USAF/AFMC AFRL FA8750-16-C-0158.
Disclaimer: The views, opinions, and/or findings expressed are those of the author(s) and
should not be interpreted as representing the official views or policies of the Department of
Defense or the U.S. Government.
This work is also supported by the Intelligence Advanced Research Projects Activity (IARPA)
via Department of Interior/Interior Business Center (DOI/IBC) contract number D17PC00345. The
U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes not
withstanding any copyright annotation thereon.
Disclaimer: The views and conclusions contained
herein are those of the authors and should not be interpreted as necessarily representing the
official policies or endorsements, either expressed or implied of IARPA, DOI/IBC or the U.S.
Government.